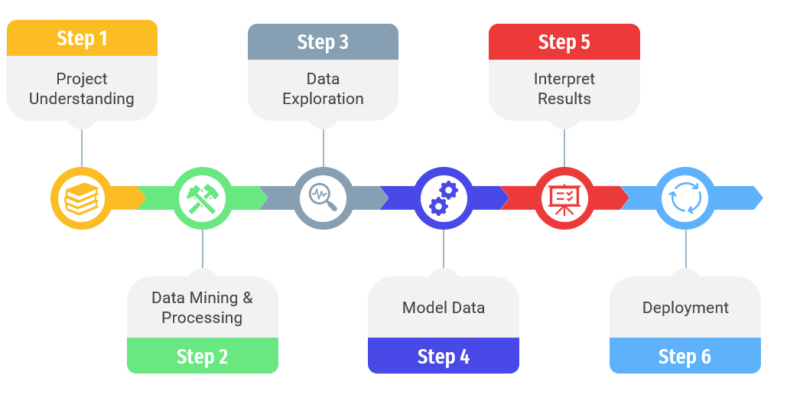
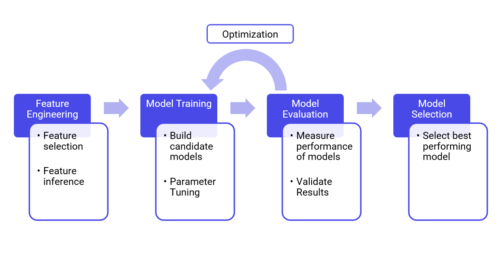
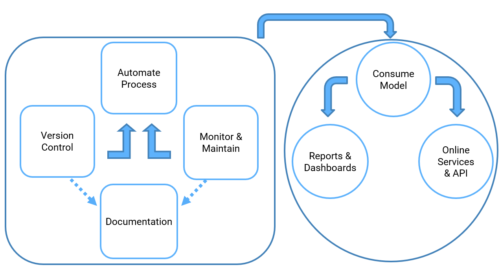
A recommender system is a filtering process which consists of suggesting relevant information to users. Rather than showing all possible information to a user at once. In the case of an online store, the purpose of a recommender system is to offer the customer, products or services, adapted to his profile. This process filters the information to a subset based on methods such as Collaborative filtering, Neighbour-based Collaborative filtering, and Content-based filtering.
Collaborative filtering methods for recommender systems are methods that are solely based on past interactions recorded between users and items to yield new recommendations. The main idea is that past user-item interactions are sufficient to detect similar users and similar items to make predictions based on the estimated proximities. The main advantage of collaborative approaches is that they require no information about users or items and, so, they can be used in many situations.
Content-based methods, on the other hand, use additional information about users and items. These methods try to construct a model based on the available features on the items, that justify the observed user-items interactions.
Several factors have influenced the use of recommender systems. The growth in digitalization, the increasing use of online platforms, and the abundance of online information has accentuated the importance for businesses and organizations to offer the right information, whether that be a product, a service or content, to the right user at the right time. Recommender systems meet this need, and have many benefits such as improve customer experience, not exclusively through relevant information, they additionally offer the correct advice and direction. Thus, engage and increase user interaction, and create the ability of tailoring and personalizing offers to users, which could ultimately lead to increase revenue depending on the business.
At Valkuren, we implemented this recommender system for an e-commerce platform to optimize the consumer experience on our client’s website. We used the predictive method to improve the product offering to consumers based on their search using purchase history and estimated proximity.
Feel free to contact us for more detail!